Inference Arbitrage: How I Route 200+ Daily LLM Calls Across Five Models
Inference arbitrage means routing each AI task to the cheapest model that can handle it at acceptable quality, instead of sending everything to the most expensive one. No benchmark tells you which model to use for which task at which price point. I published a 38-task benchmark across 15 models last week and the top finding was a routing principle, not a model name: match the model to the task, and most of your tasks don’t need the expensive one.
What Does My AI Workday Look Like?
I was on a flight last month, SSH’d into a cloud server over spotty airplane wifi, half a dozen subagents running in parallel. I watched my weekly token allocation drain faster than I’d planned, and by the time I landed I was rationing for the rest of the week.
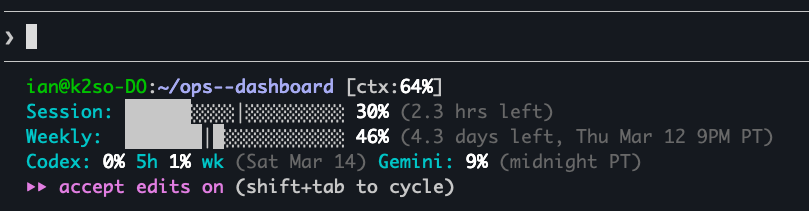
I now plan heavy jobs around the weekly reset cycle. Monday, when the budget is flush, I queue the expensive reasoning tasks. By Thursday, everything possible routes to cheaper models or defers to the next cycle.
![]()
I parsed my Claude Code logs from Feb 28 through Mar 2 and categorized every session by task type.
| Task Type | Sessions | Avg Duration | Estimated Calls/Day |
|---|---|---|---|
| Coding / system work / ops | 48 | ~45m | 50-80 |
| Data analysis | 18 | ~45m | 25-40 |
| Research | 12 | ~35m | 15-25 |
| Writing / content | 8 | ~60m | 20-35 |
| Email / comms | 3 | ~30m | 5-10 |
A typical day runs 80-120 API calls during interactive work, plus 50-200 from automated scripts. Peak days during benchmark development spiked to 7,700 calls (during benchmark automation, not typical usage). I’m a Claude Max subscriber, so take the daily-driver recommendation with that context.
The Five-Model Stack
Sonnet (Claude Code, daily driver). Where I spend most of my time. Sonnet handles everything interactive: coding, debugging, file edits, writing, planning. It scored 100% on my benchmark at $0.20/run with a 4.6s median response, and for my call volume the quality-to-cost ratio is unmatched.
Opus (escalation model). When Sonnet gets something wrong or I’m debugging a genuinely hard problem, I escalate. Opus also scored 100%, but at $0.69/run, a 3.5x premium for zero additional quality on most tasks. Where it earns that premium: ambiguous reasoning, multi-step causal chains, and problems where the first answer needs to be right because verification is expensive.
Codex subagents (cross-checking and cost spreading). I run OpenAI’s Codex CLI as a deliberately separate inference channel, spreading token consumption across subscription plans and cross-checking Opus’s work. Same problem, both models, compare answers: agreement means high confidence, disagreement tells me where to dig. GPT-5.2-codex scored 98.3% on the benchmark, and a second opinion from a differently-architected model has caught real bugs that single-model workflows miss. During one refactor last week, Codex flagged a race condition in a monitoring script that Sonnet had approved twice.
Gemini Flash CLI (research and file reads). Gemini reads local files via @file syntax, has built-in Google Search, and runs fast enough that I’ve burned through 1,000 calls in a single research sprint. I once needed founding dates and employee counts for 100 companies, and Gemini had it done in five minutes flat while Claude’s budget stayed untouched. Every Gemini query is one that doesn’t count against my Claude budget.
Qwen 3.5 35B on-prem (Mac Studio, async work). The slowest model in my stack, running through OpenClaw on a Mac Studio. Qwen handles cron jobs, overnight batch processing, and anything I can queue and forget: sovereignty (nothing leaves the machine) and cost (free after hardware), scoring 85.8% on the benchmark. Solid for extraction and code, but only 60% on reasoning. I tried it on a reasoning-heavy debugging session once and lost 20 minutes before escalating to Sonnet.
Full LM Studio setup and tuning guide for Apple Silicon.
The Routing Decision Tree
┌──────────────────┐
│ OPUS │
│ Complex reasoning│
│ $0.69/call │
└────────┬─────────┘
│
┌────────────────────┐ ┌────────┴────────┐ ┌────────────────────┐
│ QWEN LOCAL │──────────│ SONNET │──────────│ GEMINI │
│ Sensitive data │ │ (default) │ │ Research, free │
│ Overnight batch │ │ $100/mo Max │ │ @file, web search │
│ $0 (on-prem) │ │ 100% quality │ │ 1,000 calls/day │
└────────────────────┘ └────────┬────────┘ └────────────────────┘
│
┌────────┴─────────┐
│ CODEX │
│ Cross-check │
│ Diff. arch. │
│ $20/mo Plus │
└──────────────────┘Three heuristics drive most of the routing (38 tasks, so treat these percentages as directional):
- Sensitive data stays on-prem. Anything touching client work or regulated industries goes to Qwen local, regardless of quality scores.
- Reasoning tasks pay for frontier. Extraction and simple code score 100% on every model including free ones, but reasoning and planning show a 20-44 point gap between free and premium.
- Everything else defaults to Sonnet. 100% across all categories at $0.20/run, and Claude Code’s native file access makes it the only option for agentic coding loops.
I choose models at session and tool level, while Claude Code handles sub-call routing internally. In my session data, 12.2% of calls were auto-routed to Haiku for simple tasks like file reads and short bash commands, regardless of the parent session’s model.
Models, Costs, and Why Each One’s There
| Model | Tasks | Subscription | Per-Call Cost | Why |
|---|---|---|---|---|
| Sonnet (Claude Code) | Interactive coding, debugging, file edits, writing, planning | $100/mo (Max 5x) | ~$0.20/call | 100% quality, 4.6s median, native file access |
| Opus (Claude Code) | Complex reasoning, ambiguous problems, escalation | Included in Max ($0.69 at API rates) | ~$0.69/call | 3.5x premium justified on multi-step reasoning |
| GPT-5.2-codex (Codex CLI) | Cross-checking critical decisions, parallel work | $20/mo (ChatGPT Plus) | Included | Different architecture catches different bugs |
| Gemini Flash (CLI + API) | Research, web lookups, file summaries, bulk classification | $0 (free tier) | $0 | Built-in search, 1.1s response, 1,000 calls/day free |
| Qwen 3.5 (Mac Studio, local) | Overnight batch, cron jobs, extraction | $0 (on-prem) | $0 | Sovereign, 100% on extraction, 97% on code |
Total monthly spend: $120/mo. At API rates, my typical 80-120 daily interactive Sonnet calls alone would cost $480-720/mo, so the Max subscription pays for itself on volume before accounting for Opus access.
Capability Constraints and Quality Gaps by Task Type
Not every model can do everything. Before routing by quality, check whether the model even supports the capability you need.
| Model | Web Search | Usage Limits | Cost |
|---|---|---|---|
| Qwen 3.5 local | Needs API key | Single-threaded | $0 |
| Gemini Flash CLI | Yes (built-in Google) | 1,000/day free | $0 |
| Claude Code (Sonnet/Opus) | Limited (WebFetch) | 225/5hr (Max 5x) | $100/mo |
| Codex (via ChatGPT Plus) | Yes (browser) | Quota-based | $20/mo |
Quality varies dramatically by task type. These numbers come from my 38-task benchmark across 15 models, grouped by category to show where cheap models hold up and where they fall apart.
| Task Category | Free Models | Cheap Paid | Premium | Gap | Verdict |
|---|---|---|---|---|---|
| Extraction | 100% | 100% | 100% | 0 | Use cheapest |
| Simple code | 97-100% | 97-100% | 100% | 0-3% | Use cheapest |
| Complex code + reasoning | 60-100% | 80% | 100% | 13-40% | Pay for frontier |
| Writing | 77-96% | 89-100% | 97-100% | 11% | Context-dependent |
| Planning + system health | 50-94% | 94-100% | 100% | 25-44% | Pay for frontier |
| Data analysis | 75-80% | 75-95% | 95-100% | 20% | Pay for frontier |
| Investments | 83-87% | 87-100% | 87% | 2% | Use cheapest |
If the gap between free and paid exceeds 10 percentage points, pay for frontier. Below 10, free or cheap is fine, and the savings compound across hundreds of calls per week. Paying Opus rates for extraction is a 17x premium for zero quality improvement. Routing reasoning tasks to Qwen means getting the wrong answer 40% of the time.
The full quality and cost breakdown across all 15 models is in my 38-task LLM benchmark.
Routing in Practice: Three Real Examples
Web research batch (100 companies, pulling founding year, HQ, employee count, latest funding). Gemini Flash handles this in 5 minutes at $0 because it’s the only programmable option with built-in web search.
Categorize 1,000 local files. Qwen local runs overnight at $0 but takes 107 minutes; Gemini Flash finishes in 17 minutes via @file syntax. Claude Code Max could do it, but burning a $100/mo subscription on classification wastes its real value.
Clean up a 100-file codebase. Claude Code Max is the only option that autonomously navigates a repo, edits files, runs tests, and recovers from errors, so there’s no real alternative for this class of work.
What Are You Actually Paying For?
| Free Only | Split Stack | Max 5x + Supplements (my setup) | Max 20x + Supplements | |
|---|---|---|---|---|
| Monthly cost | ~$10 (electricity for the Mac Studio) | ~$40 | ~$120 | ~$220 |
| What’s included | Qwen local + Gemini free + gpt-oss-20b via OpenRouter | Claude Pro ($20) + ChatGPT Plus ($20) + Gemini free + Qwen local | Claude Max 5x ($100) + ChatGPT Plus ($20) + Gemini free + Qwen local | Claude Max 20x ($200) + ChatGPT Plus ($20) + Gemini free + Qwen local |
| Message limit | None (local), 1,000/day (Gemini) | Rolling caps on Claude Pro and ChatGPT | 225/5hr window | 900/5hr window |
| Best for | Privacy-sensitive work, budget-zero | Individual devs, <4 hrs AI coding/day | Most professional developers | Heavy agentic use, batch jobs, agent swarms |
The free tier can’t do agentic coding without building the plumbing yourself, and reasoning accuracy drops to 60%. The split stack at $40/mo gets to 95-97% quality, but Claude Pro’s rolling usage cap will hit at the worst moment, deep into a complex session. Max 5x at $100/mo is the practical sweet spot for most work: Sonnet and Opus on demand, native file access, and 225 messages per 5-hour window that most sessions don’t exhaust. The resilience side of that stack, routing the same model across two providers so one vendor pruning its catalog can’t take you down, is its own free LLM API tiers writeup.
I use Max 5x ($100/mo), and most weeks the 225-message/5hr ceiling is enough. Some weeks I barely touch it. Other weeks, batch jobs and sustained research sessions push past it by Tuesday, and I’m rationing or deferring work to the next reset window. Max 20x ($200/mo) would eliminate that ceiling anxiety, but I haven’t found the extra $100/mo justified yet. For competitive context, ChatGPT Plus runs $20/mo, Google AI Ultra hits $250/mo, and SuperGrok is $30/mo.
Provider Trust and Jurisdiction Risk
DeepSeek R1 scores 96.8% and MiniMax M2.5 hits 98.6% at $0.07/run, so the quality is genuinely competitive. The question is whether you trust the provider’s data handling. The Canadian federal government restricted DeepSeek from government devices in February 2025, BC banned it from provincial devices, and in February 2026 Anthropic alleged that DeepSeek, Moonshot AI, and MiniMax ran coordinated distillation attacks targeting Claude.
My position: less-trusted models for personal experimentation on non-sensitive data, kept away from client work or regulated industries. Running them via OpenRouter routes calls through US infrastructure, which reduces but doesn’t eliminate the risk.
Where Benchmark Meets Practice
The benchmark suggests Haiku (95.9%, $0.04/run) is the optimal cost-quality model, and Claude Code already routes Haiku-appropriate calls (short responses, file reads, simple bash) automatically. In my session data, roughly 70% of calls fit that profile.
But I also offload work to Gemini Flash that would otherwise burn Haiku calls against my Claude quota. Gemini is faster (1.1s vs 2s), has built-in web search, and doesn’t count against my Max 5x message ceiling at all. Every file summary or web lookup I route to Gemini is one fewer call ticking down my 225-message window.
Claude Code doesn’t expose per-turn routing decisions, so the gap between the optimal routing table and what the tooling actually supports is where real savings sit.
For the practitioner companion piece – what happens when a routed session fails to catch a subtle bug because the deterministic tool isn’t in the pipeline – see The LLM Kept Saying ‘Fixed.’.
FAQ
Does extended thinking burn more Claude Max quota?
Yes. Thinking tokens count against your quota, and a thinking-heavy model generates roughly 5x more tokens than standard. On Max 5x (225 messages/5hr), heavy thinking hits the ceiling 3-4x faster than standard Sonnet calls.
If I spawn a Haiku subagent from Claude Code, does that count as a Haiku call or Sonnet call?
Claude Code’s subagent routing is opaque but observable. In my session data, 12.2% of calls were routed to Haiku automatically, and subagent-heavy workflows are more quota-efficient than single-thread sessions.
Why not use an ML-based router like RouteLLM?
For my workflow (80-120 calls/day, 5 models), the routing logic fits in my head: extraction goes cheap, reasoning goes frontier, everything else defaults to Sonnet. The router overhead only makes sense at enterprise scale where per-call savings outweigh the routing infrastructure cost across millions of calls.
Should I use a thinking model for agentic coding loops?
Generally no. Thinking models add 10-25 seconds of latency above baseline per call for the reasoning phase, and in agentic loops with 50+ sequential calls that compounds to roughly 24 minutes of wall clock time versus about 1.7 minutes with Haiku at 2s per call. Use thinking models for single high-stakes decisions and fast models for the iterative loop.
Is it worth running a local model daily?
Yes, but depends on workload mix. Qwen 3.5 locally scores 100% on extraction and 97% on code, covering overnight batch jobs at zero marginal cost. The tradeoff: ~29s median response and 60% reasoning accuracy versus 100% for frontier. If you have batch work that can run overnight and care about data sovereignty, a local model pays for itself in the first month.
If you want the full build recipe for a CUDA-side local setup, I documented the from-source llama.cpp build on a Dell T5820 and RTX 3090 Ti separately, including the boot-loop fix and the production server flags. For the three months of speed tuning that followed (autoregressive baseline, DFlash, MTP, ending at 39 to 49 tok/s on a single 3090 Ti), see Three Months of Speed-Up Experiments on a 3090 Ti.
Can I use DeepSeek or other less-trusted providers for production work?
The quality is real (R1 scored 96.8%), but several governments have restricted specific providers, and Anthropic has documented distillation attacks by some. For anything touching client data, trusted providers or local only.
Companion to LLM Benchmark 2026: 38 Actual Tasks, 15 Models for $2.29, which has the full quality, cost, and speed data across all 15 models. The benchmark test suite and scoring harness are on GitHub.
<\!-- wp:paragraph -->The scraper layer feeding this pipeline uses nodriver, the only browser in my Cloudflare anti-detect benchmark with zero blocked cells across 31 production targets.
<\!-- /wp:paragraph -->Related: once the router was running, I built a dashboard to watch it and found three panels lying to me. Three Green Lies: debugging a self-hosted LLM observability dashboard.
How a CEO uses Claude Code and Hermes to do the knowledge work
A blank or generic config file means every session re-explains your workflow. These are the files I run daily as CEO of a cybersecurity company managing autonomous agents, cron jobs, and publishing pipelines.
- CLAUDE.md template with session lifecycle, subagent strategy, and cost controls
- 8 slash commands from my actual workflow (flush, project, morning, eod, and more)
- Token cost calculator: find out what each session is actually costing you
One email when the pack ships. Occasional posts after that. Unsubscribe anytime.