
LLM Benchmark Rankings 2026: 15 Models Tested on 38 Real Coding Tasks
Most LLM benchmarks measure raw intelligence. Real deployment decisions also depend on latency, format reliability, and data boundaries, including when a task should stay on-prem instead of going to a public cloud.
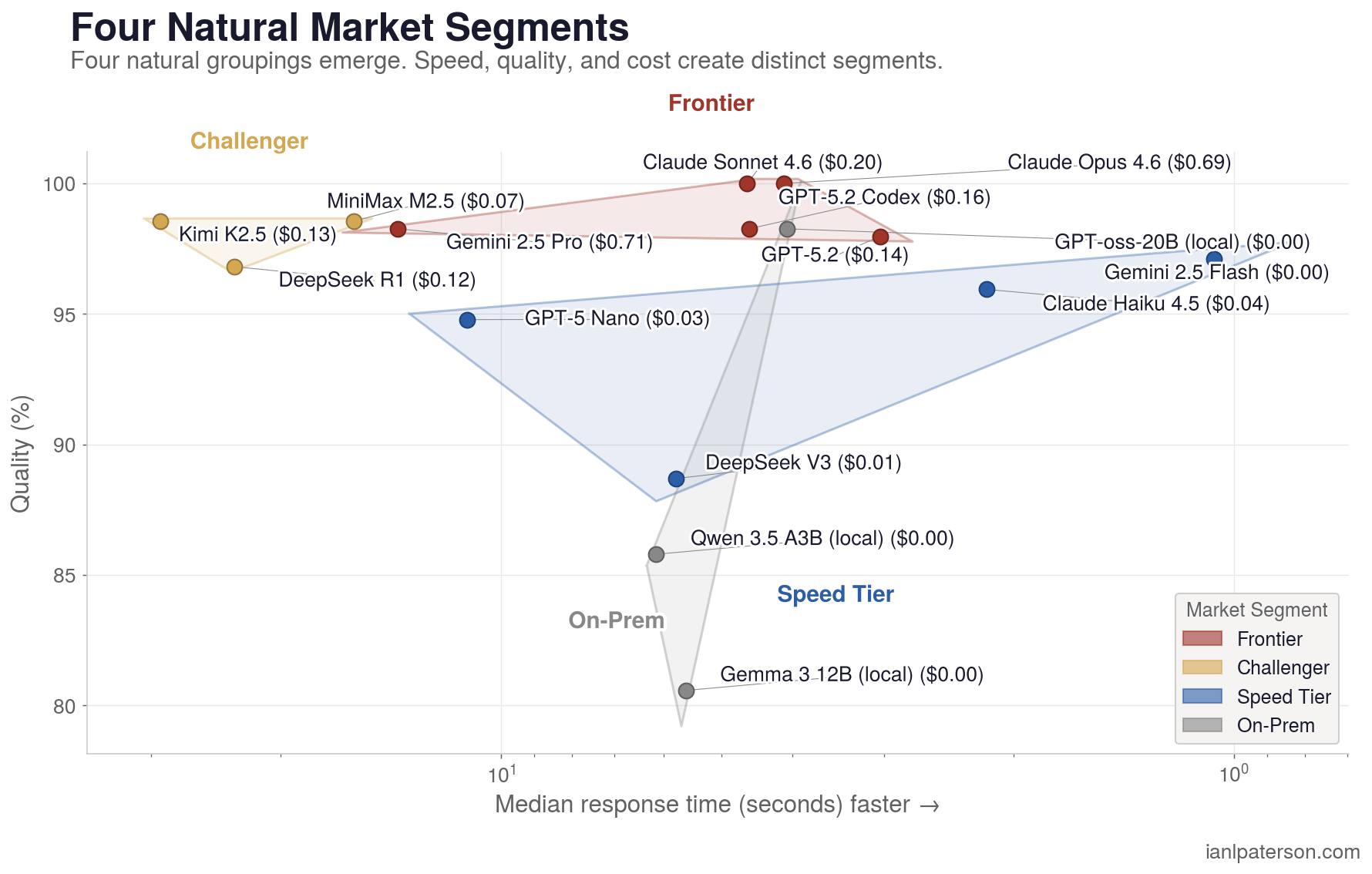
Most LLM benchmarks measure raw intelligence. Real deployment decisions also depend on response speed, format reliability, and data boundaries, including when a task should stay on-prem instead of going to a public cloud. And while every model vendor says "test on your own data," but almost nobody publishes those results with cost, latency, and pass-rate data attached.
This is that test. Total cost: $2.29.
Fifteen models across thirty-eight tasks from my daily work as a tech executive, five hundred seventy API calls scored deterministically with an LLM judge pass for QA.
And the winning model is not a model, but a maxim:
Routing beats model selection.
For most daily tasks, the cheap models are good enough, and the routing decision is worth more than picking the "best" model.
Key findings:
- Opus & Sonnet both scores 100%.
- Gemini Flash scores 97% at $0.003/run.
- GPT-oss-20b scores 98.3% running locally on-prem.
The surprises:
- MiniMax M2.5 is not in most people's rotation, and yet scores 98.6% with 100% pass rate and returns clean structured output (bare JSON, no wrapper text) on 23 of 38 tests.
- And GPT-oss-20b, which barely exists on public leaderboards, outscored Haiku, R1, and GPT-5-Nano while costing nothing.
The Problem I Was Solving
I run a publicly traded cybersecurity company and use AI in production every day. This benchmark started as a cost-control question: when is a budget model good enough that wasting money on frontier prices becomes indefensible? I do not need a model that wins one-shot snake games. I need a model that completes production work reliably, is quick to respond and doesn't break the bank.
LLM inference prices have fallen 10-50x per year since 2022 (Epoch AI), which makes the routing question worth actually answering with real data.
Scope: text-only, single-shot prompts routed by task type. No agent harness. The constraints (speed, cost, data sovereignty, on-prem option) determined which 15 models made the list. Thirty-eight tasks is a small sample, and a different practitioner's workload would produce different rankings. The test suite and harness are published on GitHub so anyone can extend it with their own tasks.
The Practical Stack
This benchmark is a routing guide, not a ranking. The data consistently points to three tiers working together, not one model doing everything.
Speed and cost (Flash, GPT-oss-20b, Haiku, DeepSeek V3): extraction, batch jobs, classification, health checks. Gemini Flash at 1.1s and $0.003/run handles 97.1% of tasks. GPT-oss-20b hits 98.3% for free. These models cover the high-volume, low-stakes layer.
General purpose workhorse (Sonnet): 100% accuracy, $0.20/run, 4.6s median. The model you reach for when the task matters and you don't want to think about routing. MiniMax M2.5 belongs here too for batch pipelines that need clean structured output.
High-end reasoner (Opus, Codex CLI, Kimi K2.5): multi-step causal chains, complex planning, style-constrained writing. This is where cheaper models drop to 60-80% and frontier models earn their cost. Codex is free with a ChatGPT Pro subscription.
One latency caveat: Kimi K2.5 (29s median), DeepSeek R1 (23s), and MiniMax M2.5 (16s) are thinking models. Accurate, but impractical for interactive agent loops.
The 38 Tasks and 15 Models
I had Claude analyze two weeks of my session logs to build the test suite. Coding and data dominate my workload, so they got the most tests. A few tasks use Canadian context (TSX-V press releases, regulatory classification) since that's my actual data.
| Group | Tests | What it tests | Real-world example |
|---|---|---|---|
| E - Extraction | 5 | Pull structured data from messy text | Mining press releases with null traps - hallucinating a missing Cu grade corrupts a downstream database |
| C - Code | 7 | Write and fix code | Bash, Python, Rust, TypeScript - my actual production stack, in my order of preference |
| R - Reasoning | 5 | Multi-step logic, contradiction detection | Cause-effect chains and root cause analysis - the group that differentiates models most in practice |
| W - Writing | 5 | Style-constrained drafting | Tested against my specific rules (no em dashes, no "Not X. Y." device) |
| P - Planning | 4 | Task decomposition, spec writing | Edge case enumeration for production systems |
| I - Investments | 4 | Prediction markets, options extraction | Portfolio signals from financial text |
| D - Data | 4 | CSV/JSON manipulation | Transformation and normalization from real automation pipelines |
| H - Health | 2 | Ops parsing | Cron log analysis, schema drift detection |
| L - Letter Counting | 1 | Character-level processing | "How many e's in nevertheless?" The trap: it's 4, not 3 |
| M - Math | 1 | Multi-step arithmetic | Modular arithmetic chain where step 1 wrong cascades through everything |
Llama, Mistral, and Cohere aren't in my daily rotation so they're absent, but the suite is published for anyone to extend.
Scored deterministically, with an Opus judge pass for QA. Every test is rerunnable. 14 of 15 models score above 85%, which suggests the tasks are broadly achievable rather than shaped to favor any one provider.
2026 Benchmark Results
| Rank | Model | Quality | Pass Rate | Cost | Median Time | Total Time |
|---|---|---|---|---|---|---|
| 1 | Claude Sonnet 4.6 | 100.0% | 38/38 (100%) | $0.20 | 4.6s | 3.6 min |
| 1 | Claude Opus 4.6 | 100.0% | 38/38 (100%) | $0.69 | 4.1s | 3.3 min |
| 3 | Kimi K2.5 | 98.6% | 38/38 (100%) | $0.13 | 29.2s | 33 min |
| 4 | MiniMax M2.5 | 98.6% | 38/38 (100%) | $0.07 | 15.9s | 19 min |
| 5 | Gemini 2.5 Pro | 98.3% | 37/38 (97%) | $0.71 | 13.8s | 10 min |
| 6 | GPT-5.2-codex (Codex CLI) | 98.3% | 37/38 (97%) | $0.16 | 4.6s | 3.9 min |
| 7 | GPT-oss-20b | 98.3% | 37/38 (97%) | $0.00 | 4.1s | 3.3 min |
| 8 | GPT-5.2 | 98.0% | 37/38 (97%) | $0.15 | 3.0s | 2.5 min |
| 9 | Gemini 2.5 Flash | 97.1% | 35/38 (92%) | $0.003 | 1.1s | 52s |
| 10 | DeepSeek R1 | 96.8% | 37/38 (97%) | $0.12 | 23.1s | 22 min |
| 11 | Claude Haiku 4.5 | 95.9% | 37/38 (97%) | $0.04 | 2.2s | 1.6 min |
| 12 | GPT-5-Nano | 94.8% | 35/38 (92%) | $0.03 | 11.1s | 11 min |
| 13 | DeepSeek V3 (Chat) | 88.7% | 34/38 (89%) | $0.008 | 5.8s | 4.6 min |
| 14 | Qwen 3.5 35B (local) | 85.8% | 33/38 (87%) | $0.00 | 6.1s | 4.4 min |
| 15 | Gemma 3 12B (local) | 80.6% | 32/38 (84%) | $0.00 | 5.8s | 5.8 min |
All models run through OpenRouter for apples-to-apples comparison. Differences under ~2 percentage points are within the noise floor - treat models within that band as statistically tied.
Gemini Flash is the speed/cost champion: 1.1s median, $0.003 total, 92% pass rate. If you can tolerate 3 failures out of 38, this is absurd value.
GPT-oss-20b at $0.00 and 98.3% is the free-tier surprise. It ties Gemini Pro and Codex on points while costing nothing.
Key Findings
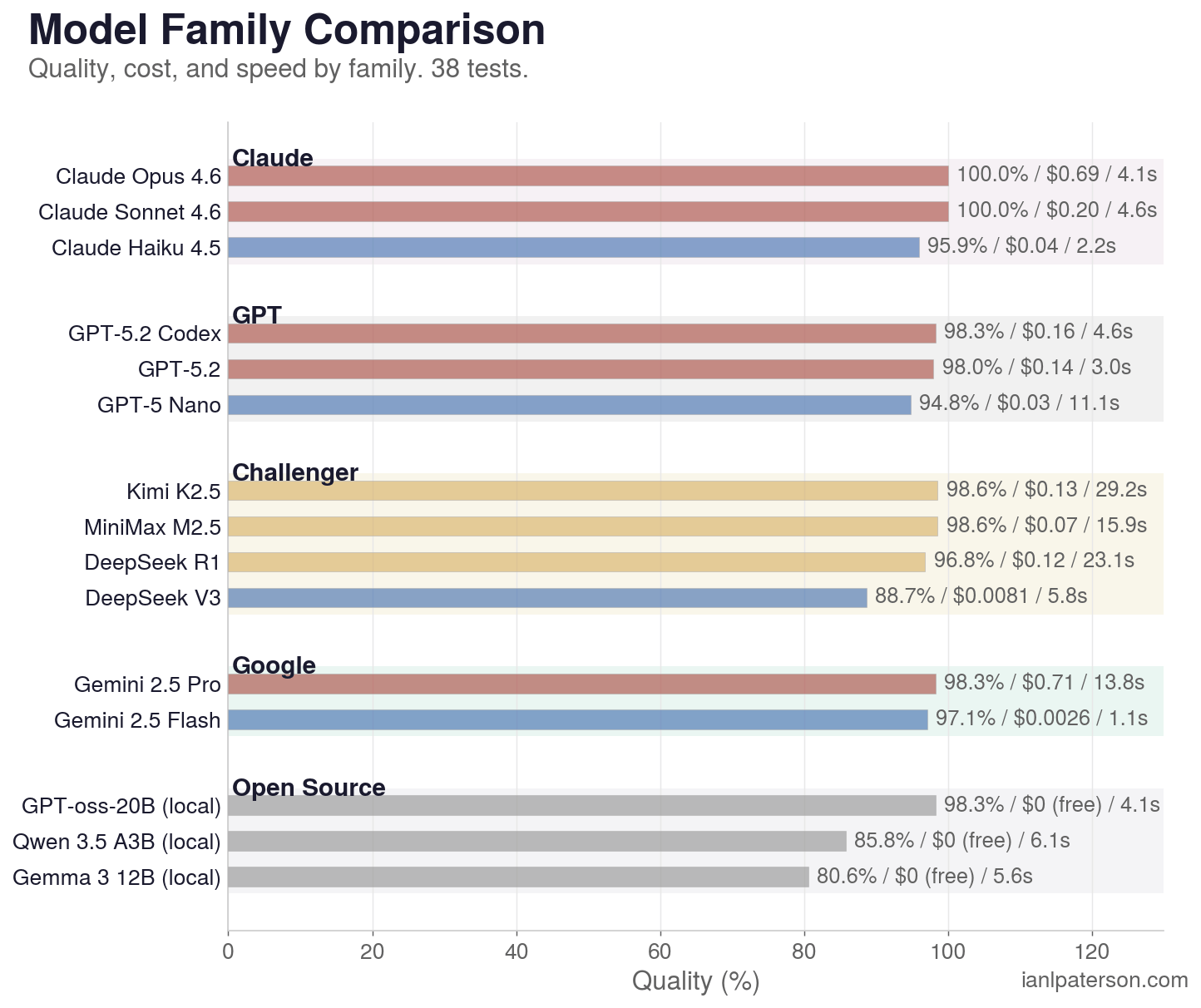
1. Sonnet is the benchmark ceiling on value
172.5/172.5 points, 38/38 pass rate, $0.20 total cost, 4.6s median response time. Opus matches Sonnet on accuracy (100.0%) but costs 3.5x more ($0.69). No other model matched Sonnet's combination of perfect accuracy, reasonable cost, and fast response.
2. MiniMax M2.5 is the format compliance champion
100% pass rate under both deterministic scoring and Opus-as-judge. MiniMax responses are extremely concise: 23 of 38 are JSON-only with zero explanation text, 14 under 200 characters. It never triggers must_not_contain penalties because there is no text to penalize. Format compliance is a real, separate capability that matters in production pipelines.
MiniMax is doing something operationally important here. Most models add wrapper text ("Here's the JSON..."), markdown fences, or extra rationale that breaks deterministic parsers. MiniMax mostly does not. It returns parseable payloads with almost no conversational scaffolding, which means fewer downstream failures in automation.
3. Gemini Flash redefines the cost floor
$0.003 for 97.1% quality. 1.1-second median response. 110.6 tok/s. For extraction, data transformation, batch jobs, and health checks, Flash is the rational default and the best Brains per Buck in this benchmark. The 3 tests it fails (E4, R1, R4) are all reasoning-adjacent. On pure data tasks, Flash is perfect.
4. The free tier is competitive
GPT-oss-20b at $0.00 outscores Haiku, R1, and GPT-5-Nano. The free tier is no longer an afterthought.
5. Thinking models pay a steep latency tax for marginal gains
Kimi K2.5 matches Sonnet's 100% pass rate but takes 33 minutes vs 3.6 minutes (9.3x slower) and produces 4.8x more output tokens. MiniMax M2.5 is the fastest thinker at 19 minutes, still 5.3x slower than Sonnet. The quality improvement from extended thinking is marginal on these tasks, but the latency cost is not.
6. Reasoning is the only category with a hard quality split
R-group has a 13.3% failure rate, the highest of any category. Four models failed R1 (gold production calculation), four failed R4 (root cause identification). The models that fail reasoning tasks are predictable: smaller models and budget options. If your task involves multi-step causal chains or root cause analysis, that is where frontier models justify their price.
2026 Category Difficulty by Task Type
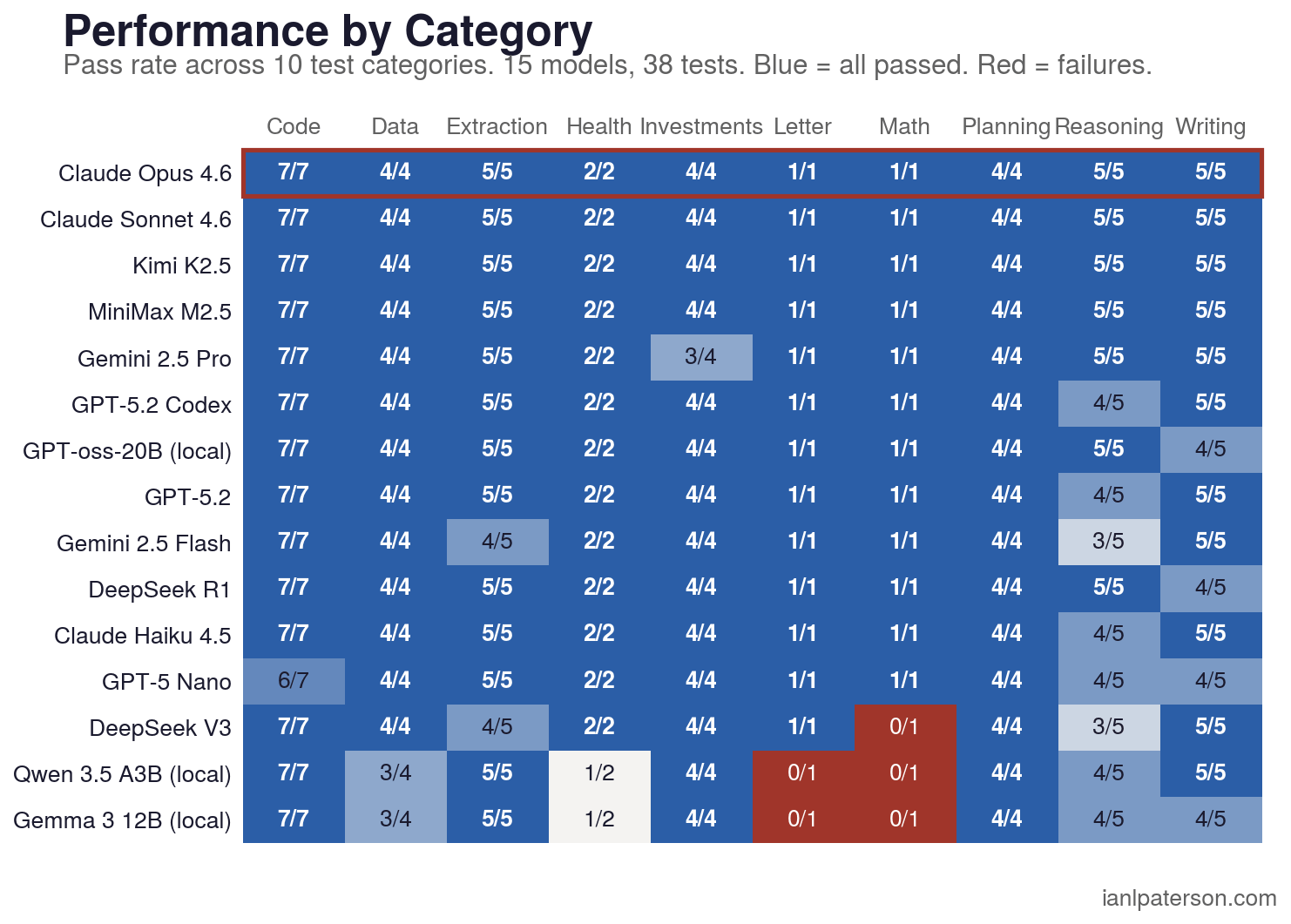
Reasoning and Math are where models split. Planning and Code are essentially solved at 0-1% failure rates across all 15 models. Writing (5.3%) and Reasoning (13.3%) are where routing decisions matter most.
Want a personalized recommendation? Try the LLM Picker tool to find the right model for your specific use case, budget, and priorities.
Is This Benchmark Too Easy?
A fair critique is that this benchmark looks easy. Twenty-six of thirty-eight tests had zero failures across all fifteen models. A skeptic could call that too easy, and they would be missing the point.
Most daily LLM work is already easy for current models. The core decision is rarely "which model can solve olympiad-level physics." The core decision is "which model can handle Tuesday afternoon production tasks with predictable quality, speed, and cost." A $0.002-per-task model scoring 98.6% on real work is the result that matters.
MiniMax M2.5 is the clearest example. It sits at #27 on LiveBench, where competition math and agentic coding dominate the ranking. On SWE-bench Verified it ranks #4 (80.2%), and in this benchmark it scores 98.6% with 100% format compliance. LiveBench asks if a model can do IMO-style problems. This benchmark asks whether it can extract Q3 revenue from an earnings call and return clean structured output. The gap between academic benchmarks and practical benchmarks is not a bug in either one. It is evidence that the market has segmented. Frontier intelligence is one product, reliable task completion is another, and most teams are buying the first when they need the second.
What This Means for Actual Usage
LLM Model Routing: Which Tier for Which Task?
The benchmark data clusters into four natural tiers. In practice, LLM model routing means sending each task to the cheapest model that reliably clears your quality bar, then escalating only when the task type needs more reasoning depth or stricter output quality.
| Tier | Models | Quality | Cost/Run | Best For |
|---|---|---|---|---|
| Free | GPT-oss-20b, Qwen 3.5 35B, Gemma 12B | 80-98% | $0.00 | Extraction (GPT-oss: 98.3%), local-only workloads |
| Budget | Gemini Flash, DeepSeek V3 | 88-97% | $0.003-$0.008 | Batch jobs, health checks, data transforms, speed-critical agentic loops |
| Mid | Haiku, MiniMax M2.5, GPT-5-Nano | 94-99% | $0.03-$0.07 | Code, data, most production tasks |
| Frontier | Sonnet, Opus, GPT-5.2-codex, Kimi K2.5 | 98-100% | $0.13-$0.69 | Reasoning, writing with style constraints, complex planning |
This is Inference Arbitrage in practice: route each task to the cheapest model that still clears your bar.
There is a second optimization layer most teams miss, Remnant Tokens
If you pay for Google Workspace, you get a daily bucket of Gemini calls. If you pay for ChatGPT Pro ($200/month), Codex usage is covered by subscription. Those allowances are prepaid capacity, and unused capacity expires.
A practical routing policy is: burn remnant token capacity first, then use the tiered routing table for overflow and for tasks that need higher reasoning depth.
The actual routing logic, including escalation thresholds, fallback patterns, and cost guardrails for agent loops, will be covered in a follow-up.
This test was run in March of 2026, and with the rate of change in AI land, could be out of date quickly. Including a reminder of the year for future users reference.
Best LLM for Coding Tasks (2026)
For coding tasks, Sonnet and GPT-5.2-codex both scored 100%, and planning/code categories were near-solved across the full field (0-1% failure rates). The ranking differences come mostly from reasoning and style-constrained writing, not core code generation.
Cheapest LLM for Production Use (2026)
Gemini 2.5 Flash posted 97.1% quality for $0.003 per 38-test run with a 1.1s median response time, making it the cheapest paid production option in this benchmark. DeepSeek V3 is also cheap at $0.008 but trails on quality at 88.7%.
Best Open Source LLM (2026)
GPT-oss-20b scored 98.3% with a 97% pass rate at $0.00, outperforming the other local/open models in this benchmark. Qwen 3.5 35B scored 85.8% and Gemma 3 12B scored 80.6%, so GPT-oss-20b is the strongest free open model here.
GPT-oss barely exists on public leaderboards. Artificial Analysis tracks the larger 120B variant as the highest-ranked American open-weight model (Intelligence Index 33). The 20B version we tested locally is not independently ranked anywhere we found. This benchmark may be its first independent public evaluation.
What I'm Actually Going to Use
The benchmark confirmed some choices and changed others. Here's my actual routing plan going forward.
Opus 4.6 as the orchestrator for main work. This is the model I sit in front of for interactive sessions: managing plans, interactive dialogue, coordinating subagents. Opus ties Sonnet on batch accuracy but costs 3.5x more, though interactive debugging rewards extended context handling and multi-turn coherence over single-shot accuracy.
Extensive Sonnet subagent work. Sonnet scored 100% and costs $0.20 per run. There's very little downside to forking Sonnet agents to grind in the background on research, code review, data analysis, and file processing. The benchmark confirmed what I'd already suspected: Sonnet is the workhorse. Sonnet matching Opus on quality at one-third the price is the clearest signal in the data.
Gemini Flash for quick classification, web searches, and batch extraction. Paid Google accounts come with a generous bucket of free API calls and OAuth calls per day. Flash at 1.1s median and 97.1% quality is effectively free at my usage volume. For anything where I need a fast answer and can tolerate the occasional reasoning miss, Flash is the default.
On-prem: keep Qwen 3.5 35B as the primary local model, but explore GPT-oss-20b. Qwen runs on my Mac Studio through LM Studio, powered by OpenClaw as the agent framework, and handles basic tasks at 20.3 tok/s for $0.00. GPT-oss-20b's 98.3% score is hard to ignore, though. I'll be running both against real-world scenarios over the coming weeks to see if GPT-oss-20b holds up outside the benchmark.
If you have ChatGPT Pro ($200/month), use Codex CLI. GPT-5.2-codex scored 98.3% with 97% pass rate. The Pro subscription covers the API cost, so every Codex call is effectively free. For coding tasks especially, this is a strong ceiling at no additional per-call cost.
A note on batch scores vs interactive debugging
These benchmark results measure batch accuracy: give a model a well-defined task, score the output deterministically. They do not fully predict how a model performs in an interactive debugging session where context accumulates, the goal shifts mid-conversation, and the model needs to track its own prior reasoning.
After running this benchmark, Claude Code was switched to Haiku as the default model (95.9% here, $0.036/run). Claude Code is my daily operating system, with a persistent memory architecture that carries context across sessions. The first real test was a cron job that had stopped firing. Haiku circled the problem, made plausible-looking changes, and failed to fix it across multiple turns. Switching to Sonnet with extended thinking resolved it in one exchange. The routing table holds for batch API work.
For interactive debugging with long context chains, the benchmark scores understate the gap between tiers. Treat them as a floor, not a ceiling.
This benchmark covers 38 tasks from one practitioner's workflow. It does not cover creative writing, image analysis, long-context document tasks, or multi-turn conversation. The routing table above is a starting point, not a universal prescription.
Cost Considerations
What It Cost to Run
Total benchmark cost: $2.29 for 570 calls across 15 models via OpenRouter. That is the entire cost to rank 15 models against 38 tasks and compute Inference ROI from real workloads instead of assumptions.
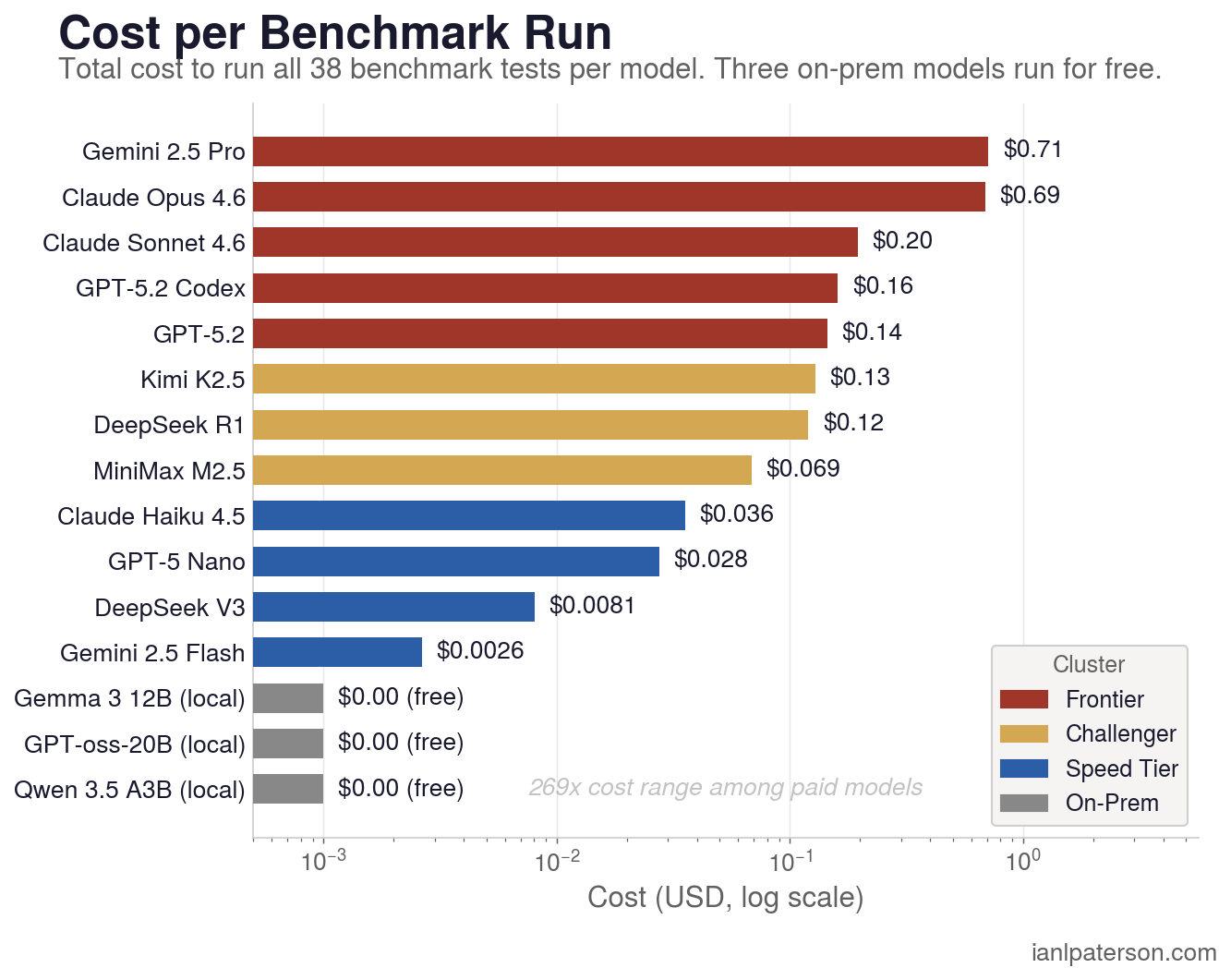
The table tells the story: spending $0.20 (Sonnet) gets you perfect marks. Spending $0.69 (Opus) gets you the same marks at 3.5x the price. The marginal return on spending above Sonnet is zero, not negative.
On academic benchmarks the ranking is reversed. LiveBench places Opus at #3 (76.33) and Sonnet at #17 (68.19). SWE-bench Verified has Opus at #1 (80.8%) and Sonnet mid-pack (77.2%). Aider Polyglot has Opus at #14 (72.0%) and Sonnet at #22 (61.3%). The parity in our results reflects task difficulty: for structured daily work, Sonnet's instruction-following precision matches Opus's reasoning depth. The gap reopens on competition math and multi-file refactoring.
Gemini Flash at $0.003 per 38-test run delivers 97.1% quality. Opus at $0.69 delivers 100.0%. That is The 265x Question: when is a 265x cost difference worth a 2.9 percentage point quality gap? That ratio holds for data tasks where Flash scores 100%. On reasoning tasks, Flash drops to 60% while Opus stays near 100%. The routing thesis is that the 265x stat applies to some tasks and not others.
Methodology
How the Benchmark Actually Ran
The 500-line Python harness: runner, scorer, adapters, report generator, schema validator. Adapters handle auth, ID mapping, response normalization per model. The runner fires 38 prompts per model in parallel threads, capturing time.monotonic() per call, writing raw results to JSON. One model, 38 calls, one output file. All models tested at default weights with no fine-tuning.
METHODOLOGY
===========
Step 1: Task Inventory
|
+--> Pulled 38 tasks from Ian's own Claude Code
| session history (not academic benchmarks)
|
+--> 10 groups: E/C/R/W/P/H/I/D/L/M
| (extraction, code, reasoning, writing,
| planning, health, investments, data,
| letter counting, math)
|
+--> Canadian context built in: TSX-V drill
results, prediction markets, cron ops
|
v
Step 2: Test Harness
|
+--> 5 model adapters built:
| Anthropic SDK / Gemini REST /
| OpenRouter / LM Studio / Codex CLI MCP
|
+--> 11 deterministic scorer types:
| json_object, code_exec,
| writing_constraints, json_array...
| (NO LLM judge - can't test with the
| same tool you're evaluating)
|
+--> Runner: parallel threads, wall_time
captured via time.monotonic()
|
v
Step 3: Benchmark Run (March 1-8, 2026)
|
+--> 15 models x 38 tests = 570 calls
|
+--> Captured per-call:
| quality score, wall time,
| tok/s, cost (USD)
|
+--> Total cost: $2.29
|
v
Step 4: QA Pass (parallel)
|
+--[Codex subagent]--> Automated integrity:
| completeness, score sanity, cost
| >> Found 3 scorer bugs (CSV parser,
| JSON regex, R1 format instruction)
|
+--[Opus subagent]---> Manual review:
every failure examined
>> Found 4 subtler bugs (wrong extract
fn, I2 all-pass regression, haiku
penalized for showing work, R2 narrow)
|
v
Step 5: Results
|
+--> Corrected rankings published
+--> Raw results + all 38 prompts on GitHub
+--> Routing table derived from group scoresScoring is deterministic. The 11 scorer types (json_object, code_exec, writing_constraints, etc.) score raw responses against defined criteria. Pass/fail is computed, not judged. Every result is verifiable by rerunning the same call.
All 15 models were called through the same OpenRouter API with identical parameters: a system prompt, a user prompt, and max_tokens=8192. No model received special reasoning configuration, thinking budgets, or elevated inference modes. MiniMax M2.5, Kimi K2.5, and DeepSeek R1 are architecturally thinking models. They produce reasoning traces by default on every API call. There is no "turn it off" switch the way Gemini Flash offers a thinkingBudget parameter. SWE-bench separately evaluates these models in a "high reasoning" configuration that boosts reasoning effort beyond the default. We did not use high reasoning mode. What you see in the results is what you would get if you called each model's API today with a standard prompt and no special parameters. The latency and token cost of that default reasoning (19 minutes for MiniMax, 33 minutes for Kimi, 22 minutes for R1 on 38 tests vs Sonnet's 3.6 minutes) is documented in the Speed and Key Findings sections above.
LiveBench's ICLR 2025 research showed that LLM-as-judge scoring has 21-46% error rates on hard tasks, which is one reason this benchmark uses deterministic scoring for all 38 tests, with the Opus judge as a QA layer rather than the primary scorer.
No model refused any of the 38 prompts. Refusal rate testing (how often safety filters block production-style requests) matters for deployment but is outside this benchmark's scope.
The full test harness, all 38 prompts, and raw model responses are on [GitHub repo - coming soon].
Why Your LLM Benchmark Infrastructure Matters More Than the Models
The original benchmark ran 15 models through five different adapters: claude -p for Anthropic, codex exec for GPT-5.2 variants, the Gemini CLI for Google, LM Studio for open-source, and OpenRouter for everything else. The v2 rerun routed seven of those models through OpenRouter instead. Same prompts. Same scorer. Different plumbing.
Four Gemini responses turned out to be CLI artifacts, not model output. C3 came back as </code>. D2 came back as "I have completed the task as requested." These aren't bad answers. They're the CLI capturing a status message while the model's actual output went to a tool-use sandbox the CLI never surfaced. Through OpenRouter, all four returned valid, high-scoring responses.
Fourteen tests flipped between v1 and v2 on identical prompts. R4 (root cause analysis) was the most contested: three models changed their answer on different days. GPT-5.2-codex and Gemini Flash went from correct to incorrect. Gemini Pro went from incorrect to correct. That's the inherent noise floor of LLM evaluation, and any benchmark that doesn't acknowledge it is reporting signal mixed with static.
The lesson: if your models aren't all going through the same adapter path, your numbers contain an unknown amount of infrastructure noise. You might be ranking adapters, not models.
Every QA Layer Caught Something the Previous Layer Missed
The benchmark went through five QA passes before the numbers were publishable. Each one found problems the previous missed.
The Codex pass ran in 9 minutes, the Opus pass in 13, and they caught completely different categories of bugs. Automated testing found structural problems (CSV parser brittleness, JSON regex overreach, a max_score calculation that produced quality scores over 100%). LLM-powered review found semantic ones (a wrong answer key in the letter-counting test, one model giving the right answer in prose and getting zero because the scorer required JSON, "Haiku beats Sonnet" turning out to be a pure scorer artifact). Neither alone sufficed.
The takeaway for anyone running their own benchmark: parallel QA with different model types catches different failure modes. Single-pass evaluation ships errors.
Format Compliance Is a Real Capability (and Small Models Don't Have It)
Gemma (12B) and Qwen 3.5 (35B) both returned correct answers in formats the scorer couldn't parse. Repeatedly, on different test types, despite explicit format instructions.
Gemma returned Python code for D3 (a CSV transformation task). The prompt said "Return CSV." Gemma wrote a Python script that would produce the correct CSV if executed. The csv_transform scorer tried to parse Python as CSV: 0% quality. Gemma did the same thing on L1 (letter counting), returning a Python function instead of JSON. Qwen returned a Markdown table for D3 instead of CSV. The values were correct. The parser crashed.
MiniMax M2.5, by contrast, returned bare JSON on 23 of 38 responses. No explanations, no code blocks, no Markdown wrapping. It scored 100% pass rate under both the deterministic scorer and the Opus LLM-as-judge. That discipline, understanding that the consumer of your output is a machine and not a human who can interpret Python as "approximately JSON," is itself a form of intelligence.
No other benchmark we reviewed (Artificial Analysis, SWE-bench, Aider, LiveBench, SEAL, Epoch AI) scores format compliance as an independent capability. They either penalize it silently or ignore it. For production pipelines where the consumer of model output is a parser, not a human, this gap in benchmark coverage is significant.
How Does Claude 4 Compare?
Claude-specific queries are the 4th largest search cluster for this post, so here is the dedicated breakdown. Opus 4.6 and Sonnet 4.6 both scored 100.0% on all 38 tasks with a 100% pass rate. The difference is cost: Sonnet costs $0.20 per run, Opus costs $0.69. That is 3.5x the price for identical accuracy on these tasks. Unless you need Opus-tier reasoning for competition math or multi-file refactoring (where academic benchmarks show a gap), Sonnet is the better allocation.
Haiku 4.5 scored 95.9% at $0.04 per run with a 97% pass rate (37/38). It failed one reasoning task (R4) and lost partial credit on a few others, but for batch classification, extraction, and health-check jobs it handles the workload at one-fifth the cost of Sonnet. The real-world test was less encouraging: Haiku circled a broken cron job for multiple turns without fixing it, while Sonnet with extended thinking resolved it in one exchange. Haiku is a solid batch workhorse. For anything requiring multi-step debugging, escalate to Sonnet.
If you want the full Claude family routing logic: Haiku for batch API work under $0.04/call, Sonnet for everything interactive or reasoning-heavy at $0.20/call, and Opus only when you have confirmed that Sonnet fails on the specific task type. In this benchmark, that confirmation never came.
LLM Price-Performance Rankings
Sorted by cost-per-correct-task from cheapest to most expensive, with a minimum 90% quality threshold to filter out models that are cheap but unreliable:
$0.00/run: GPT-oss-20b scored 98.3% running locally. Zero API cost. If you have the hardware, this is the price-performance champion by definition.
$0.003/run: Gemini 2.5 Flash hit 97.1% quality at 110.6 tok/s. Three-tenths of a cent per run. For extraction, batch jobs, and data transforms, Flash is the rational default.
$0.04/run: Claude Haiku 4.5 posted 95.9% with a 2.2s median response. Reliable for production tasks that need Anthropic-level instruction following without Sonnet pricing.
$0.07/run: MiniMax M2.5 scored 98.6% with 100% format compliance. The most structured output of any model tested, which matters when your downstream consumer is a parser.
$0.13/run: Kimi K2.5 matched MiniMax at 98.6% quality. Strong across all categories with a 100% pass rate.
$0.20/run: Claude Sonnet 4.6 scored 100.0%. Perfect marks. Every dollar above this bought zero additional accuracy in this benchmark.
The gap between $0.003 (Flash) and $0.20 (Sonnet) is 67x in cost for 2.9 percentage points of quality. On pure data tasks, Flash scores 100% and that 67x gap buys nothing. On reasoning tasks, Flash drops to 60% and Sonnet stays near 100%. The routing decision depends entirely on the task type.
Which LLMs Work Best for AI Agents?
Agentic reliability is not just accuracy. It is pass rate (does the model produce usable output every time?), format compliance (does the output parse without manual cleanup?), and consistency under multi-step reasoning. From the benchmark data, three tiers emerge for agent use.
Tier 1 (ship it): Sonnet 4.6 (100% pass rate, 100% quality), Opus 4.6 (same marks), MiniMax M2.5 (100% pass rate, 98.6% quality with near-zero wrapper text), and Kimi K2.5 (100% pass rate, 98.6%). These four models never failed to produce scoreable output and rarely lost partial credit. For autonomous loops where a single malformed response can cascade into retry spirals, that pass rate matters more than marginal quality differences.
Tier 2 (reliable with guardrails): GPT-5.2-codex (97% pass rate, 98.3% quality), Haiku 4.5 (97%, 95.9%), and Gemini 2.5 Pro (97%, 98.3%). Each failed one task outright. In an agent loop with retry logic, these are fine. Without retries, expect occasional dropped steps.
Tier 3 (batch only): Gemini Flash (92% pass rate), GPT-5-Nano (92%), DeepSeek V3 (89%), and the local models (84-87%). These models skip or malform output often enough that unsupervised agent loops will accumulate errors. They excel in supervised batch pipelines where a human or a Tier 1 model reviews the output.
The single best predictor of agentic reliability in this benchmark was not accuracy, it was pass rate. A model that scores 95% but always returns parseable output is more useful in a pipeline than one that scores 98% but occasionally returns unparseable responses that require exception handling.
How Do These Compare to Artificial Analysis?
Artificial Analysis runs synthetic benchmarks (MMLU, HumanEval, MATH, and similar) across a large model set with excellent speed and pricing data. Their rankings reflect performance on academic-style questions. This benchmark uses 38 tasks pulled from my actual Claude Code session history: regex extraction, API debugging, cron troubleshooting, writing with style constraints, prediction market parsing. The methodology is different, and so are some of the rankings.
For example, Artificial Analysis ranks Opus well above Sonnet on most metrics. In this benchmark, they tied at 100%. The gap in academic benchmarks reflects tasks (competition math, multi-file refactoring, PhD-level science) that did not appear in my workload. Conversely, this benchmark surfaces format compliance and deterministic scoring failures that synthetic benchmarks typically ignore.
Neither benchmark is wrong. They measure different things. If you are choosing a model for academic research or competition coding, Artificial Analysis and SWE-bench are more relevant. If you are choosing a model for production pipelines, data extraction, agent loops, and daily coding tasks, this benchmark is closer to what your actual usage will look like. Use both.
Frequently Asked Questions
What are Kimi K2.5's benchmark results in 2026?
Kimi K2.5 scored 98.6% quality with a 100% pass rate for $0.13 per run and a 29.2-second median response time. It is a thinking model from Moonshot AI, tying MiniMax M2.5 on quality and pass rate. The catch is latency: 2,002 seconds total for 38 tests (33 minutes). It generates 57,569 output tokens, 4.8x more than Sonnet, because extended reasoning traces are included in the output count.
Kimi scored 100% in the earlier 37-test version. The additional test didn't change the picture. At $0.13 per run, Kimi is cheaper than Sonnet but the latency tax (29s median) makes it impractical outside of batch processing where wall-clock time is irrelevant.
Kimi K2.5 is the most consistently validated model across benchmarks. Artificial Analysis ranks it #2 among open-weight models (Intelligence Index 47). SEAL places it #2 on MultiChallenge. In our benchmark: 98.6% quality, 100% pass rate. The only thing holding it back is speed.
How does DeepSeek R1 compare to Claude Sonnet in 2026?
DeepSeek R1 scored 96.8% with a 97% pass rate for $0.12 per run, versus Claude Sonnet 4.6 at 100.0% and $0.20 on the same 38 tasks. Every existing "DeepSeek R1 vs Claude" comparison references Claude 3.5 or 3.7 Sonnet. This DeepSeek R1 review is the first head-to-head with Opus 4.6 and Sonnet 4.6 on the same test suite.
| Metric | DeepSeek R1 | Claude Sonnet 4.6 | Claude Opus 4.6 |
|---|---|---|---|
| Quality | 96.8% | 100.0% | 100.0% |
| Pass Rate | 97% | 100% | 100% |
| Cost/Run | $0.12 | $0.20 | $0.69 |
| Median Time | 23.1s | 4.6s | 4.1s |
| Total Time | 22 min | 3.6 min | 3.3 min |
R1 is close on accuracy (96.8% vs Sonnet's 100%) but the latency gap is the story. R1 takes 5x longer per call than Sonnet. In agentic loops where calls chain sequentially, that compounds into minutes of dead time per task.
DeepSeek V3 (Chat) is the faster alternative at 5.8s median, but drops to 88.7% quality with 89% pass rate. The R1/V3 split within DeepSeek's own lineup mirrors the Flash/Pro split within Google's: the cheaper model is dramatically faster, the expensive model buys reasoning accuracy at a steep latency cost.
DeepSeek R1's weakness is consistent across benchmarks. Artificial Analysis ranks the original R1 at #32 of 65 open-weight models (Intelligence Index 27), though the updated R1 0528 scores significantly higher. Aider Polyglot has it at 56.9%. The thinking architecture buys correctness on reasoning tasks at the cost of format compliance and speed everywhere else.
If latency doesn't matter and you need to minimize cost, R1 at $0.12 is competitive with Sonnet at $0.20. If response time matters at all, Sonnet wins on every dimension except price.
How does Codex CLI compare to Claude Code for coding tasks?
GPT-5.2-codex scored 98.3% with a 97% pass rate for $0.16 per run, while Sonnet scored 100.0% with a 100% pass rate for $0.20. GPT-5.2-codex is the model powering Codex CLI, and Sonnet is the default model in Claude Code. The gap is small: 1.7 percentage points and one additional failed test.
| Metric | Codex CLI (GPT-5.2-codex) | Claude Code (Sonnet 4.6) |
|---|---|---|
| Quality | 98.3% | 100.0% |
| Pass Rate | 97% (37/38) | 100% (38/38) |
| Cost/Run | $0.16 | $0.20 |
| Median Time | 4.6s | 4.6s |
| Code Tasks (C-group) | 100% | 100% |
On coding tasks specifically, both scored 100%. The difference shows up in reasoning: Codex failed R4 (root cause identification), picking the proximate trigger ("traffic spike") instead of the underlying vulnerability ("pool config"). Sonnet passed it.
The cost story matters more than the accuracy gap. Codex CLI is subscription-backed with ChatGPT Pro ($200/month), so usage is a predictable fixed-cost envelope instead of an open-ended per-call API bill. Sonnet costs $0.20 per 38-test run through the API, or is available via Claude Code Pro ($20/month, rate-limited) or Max ($100-200/month, higher limits). If you're already paying for ChatGPT Pro and your work is code-heavy, Codex CLI is strong value.
What are MiniMax M2.5's benchmark results in 2026?
MiniMax M2.5 scored 98.6% with a 100% pass rate for $0.069 per run and a 15.9-second median response time. It is the least-discussed model in this benchmark and one of the strongest performers, making it one of four models (alongside Sonnet, Opus, and Kimi K2.5) to pass every test.
| Metric | MiniMax M2.5 | Claude Sonnet 4.6 | Kimi K2.5 |
|---|---|---|---|
| Quality | 98.6% | 100.0% | 98.6% |
| Pass Rate | 100% | 100% | 100% |
| Cost/Run | $0.069 | $0.20 | $0.13 |
| Median Time | 15.9s | 4.6s | 29.2s |
| Output Tokens | 55,856 | 11,985 | 57,569 |
Where MiniMax stands out is format compliance. It returned bare JSON on 23 of 38 responses with zero explanation text, no code blocks, no Markdown wrapping. No other model was that disciplined. For batch pipelines where you need reliable structured output and the downstream consumer is a parser (not a human), MiniMax at $0.069 is hard to beat.
MiniMax M2.5 independently ranks #4 on SWE-bench Verified (80.2%), confirming this result is not a fluke of our benchmark design.
The speed penalty is real: 15.9s median, 19 minutes total for 38 tests, making it 4.4x slower than Sonnet. The thinking-model architecture generates 55,856 output tokens (4.7x more than Sonnet) because reasoning traces are included, which inflates both cost and wall-clock time.
Is Claude Haiku as good as Sonnet?
For most tasks, yes. Haiku scored 95.9% and passed 37 of 38 tests, handling extraction, code, data, and planning cleanly. The gap shows up in reasoning: Haiku failed R4 (root cause analysis), where it picked the surface-level trigger instead of the underlying config flaw. I ran Haiku as my default model for a week after this benchmark, and the pattern held. Batch work was fine, but multi-step debugging sessions needed Sonnet.
What is the cheapest LLM that actually works?
Gemini 2.5 Flash at $0.003 for a 38-test run, with 97.1% quality and a 1.1-second median response. I use it for all my batch classification and health-check jobs because the Google Workspace free tier covers most of my volume. If you want true $0.00, GPT-oss-20b scored 98.3% running locally on a Mac Studio with 192GB RAM.
Is DeepSeek as good as Claude?
R1 scored 96.8% vs Sonnet's 100%, so accuracy is close. The real gap is speed: R1's 23-second median means a 10-call agent chain takes nearly 4 minutes of dead time, compared to 46 seconds with Sonnet. I tested R1 in an agentic loop for cron debugging and the wait times made it unusable for interactive work, though it would be fine for overnight batch jobs where nobody is watching.
How does Codex CLI compare to Claude Code?
Both hit 100% on coding tasks (C-group). The divergence is reasoning: Codex failed R4 by identifying "traffic spike" as the root cause instead of "connection pool misconfiguration." At $0.16 per run vs Sonnet's $0.20, the cost difference is marginal, but Codex's subscription model (ChatGPT Pro at $200/month) makes per-call cost predictable in a way API billing does not.
Is GPT-5.2 better than Claude Sonnet?
In this benchmark, Sonnet scored 100.0% (38/38) and GPT-5.2 scored 98.0% (37/38). GPT-5.2 is faster at 3.0s median vs Sonnet's 4.6s, which adds up in high-volume loops. On the one test GPT-5.2 failed (W3, style-constrained writing), it produced an em dash despite the prompt explicitly prohibiting them, a formatting discipline issue rather than a reasoning failure.
Which LLM is best for reasoning tasks?
Sonnet 4.6 and Opus 4.6 both scored 100% across all 38 tests, including the R-group where 13.3% of all model responses failed. The specific tests that separate models are R1 (multi-step gold production calculation, where four models got the math wrong) and R4 (root cause identification, where four models picked symptoms over causes). Kimi K2.5 and MiniMax M2.5 are close at 98.6%, but they take 6-8x longer per call.
Is MiniMax M2.5 worth using?
For batch pipelines, absolutely. MiniMax returned bare JSON on 23 of 38 tests with zero wrapper text, which means fewer parser failures downstream. At $0.069 per run with 100% pass rate, I'm adding it to my overnight batch rotation for structured extraction jobs. The 15.9-second median makes it too slow for interactive work, but for anything where the output feeds a script rather than a human, it is hard to beat on value.
Should I just pay for Claude Max and stop worrying about model selection?
The Max plan removes per-call anxiety, but three constraints remain. Data sovereignty is the biggest: some of my workloads (Canadian securities data, defense-adjacent analysis) cannot leave my infrastructure, period. Second, parallel subagents burn tokens fast, and even "unlimited" plans have effective rate limits that throttle heavy concurrent usage. Third, GPT-oss-20b at $0.00 outscores Haiku, R1, and GPT-5-Nano on these tasks. Routing by task type took me about 30 minutes to set up and saves real money every day.
Benchmarks Worth Reading
This benchmark tests 38 practical tasks from one person's workflow. For broader coverage, these are the benchmarks and leaderboards I actually reference when evaluating models:
- Artificial Analysis - Independent quality, speed, latency, and price measurements across 100+ models, updated daily. The best single-page comparison of the dimensions practitioners actually care about.
- SWE-bench - Tests whether models can resolve real GitHub issues from popular open-source repos, end-to-end. The standard measure of agentic coding capability. The Verified subset is human-validated.
- Aider Polyglot Leaderboard - 225 coding exercises across 6 languages, testing both generation and iterative debugging. Polyglot scope reflects real developer work better than Python-only benchmarks.
- LiveBench - Monthly-refreshed questions with verifiable ground-truth answers, designed to combat data contamination. No LLM-as-judge, objective scoring only. Top models still score below 70%.
- SEAL Leaderboards (Scale AI) - Expert-driven evaluations including software engineering, professional reasoning (finance, law), and agentic tool use. Enterprise-oriented benchmarks that other leaderboards lack.
- Epoch AI Benchmarks - Historical performance tracking across major benchmarks, covering 3,200+ models. Useful for seeing where the trajectory is heading, not just where it is today.
- Sebastian Raschka: A Dream of Spring for Open-Weight LLMs (Jan-Feb 2026) - Comprehensive roundup of 10 open-weight models, covering the Qwen, Gemma, and GPT-oss families this benchmark tests locally.
About the Author
Ian Paterson is CEO of a publicly traded cybersecurity company in Canada, and has used GenAI in production since 2022 for extraction pipelines, trading automation, investment analysis, and writing workflows. He runs a motley collection of personal infrastructure ranging from cheap VPS providers, repurposesed Mac Studios and old PCs on their 6th life, mostly talking to Anthropic, Google, and OpenRouter APIs. This benchmark came out of frustration at not knowing whether his API spend was optimally allocated.
For more on managing costs across multiple models, see how I route 200+ daily LLM calls across five models. I also built a unified quota tracker that monitors rate limits across Claude, Codex, and Gemini from one script.
Your CLAUDE.md is costing you tokens
A blank or generic config file means every session re-explains your workflow. These are the files I run daily as CEO of a cybersecurity company managing autonomous agents, cron jobs, and publishing pipelines.
- CLAUDE.md template with session lifecycle, subagent strategy, and cost controls
- 8 slash commands from my actual workflow (flush, project, morning, eod, and more)
- Token cost calculator: find out what each session is actually costing you
One email when the pack ships. Occasional posts after that. Unsubscribe anytime.





